Hillary's Inbox
As the presumptive Democratic presidential candidate, Hillary Clinton has come under fire for using a private email server to send work-related emails during her time as Secretary of State. Through Freedom of Information Act (FOIA) requests, Clinton has released batches of these emails, with the final batch released in February. While the FBI investigation is still ongoing — in particular, with regards to Clinton’s use of an unsecure home server and whether she was complicit in sending classified information — media outlets have taken interest in just what Hillary was sending and receiving and to whom. The Wall Street Journal has an interactive piece where readers can search through recipients and email text; Politco ran a story on the 23 must-read emails in her inbox.
I was curious about her emails beyond looking at individual emails, though. In order to take a comprehensive look at Clinton’s emails, I came up with a few questions I was interested in answering centering around vocabulary differences, sentence length and topics that Hillary and her email recipients talked about. In order to answer these questions, I employed concepts in NLP like k-means clustering and topic analysis using latent direlect allocation (LDA).
Here are a few hypotheses that I tested:
- The topics of emails sent between Hillary and her staffers is going to differ from topics of emails sent to people outside her office.
- There’ll be a difference in vocabulary between males and females, and between staffers and outsiders (senators, outside advisors, etc). I wasn’t sure what the vocabulary difference would be across gender, but I did think the vocabulary size in emails exchanged between staffers would be smaller than vocabulary in other emails because the email content was likely logistical details versus more expository content.
- Hillary sends shorter emails in the morning, and the length of these emails get longer in the evening. She’s likely in meetings in the morning and afternoon and likely doesn’t have time to send more than short requests and status updates.
A tale of two classification methods: k-means clustering versus LDA topic modeling
Inspired by Edwin Chen’s blog post on doing a topic analysis of Sarah Palin’s released emails a few years ago, I decided to use a LDA analysis to extract topics from all the emails in the dataset. After running LDA on a corpus, we can compare individual documents to the LDA model to see what percentage of each topic the document contains. In the context of this project, what that means is that I ran LDA on all of the emails in the dataset and then compared “documents” — in this case, all emails sent from females, or all emails sent from Colin Powell — and noted which percentage of each topic the email text contained.
Before I ran any analyses though, I needed a way to classify recipients and senders in this dataset. I turned to a helpful article published by McClatchy and grouped together people based on demographics. For example, I created a category for ambassadors, since I noticed there were four ambassadors among email recipients in addition to a category for staffers. I also classified emails by gender, regardless of role.
In addition to grouping together emails by categories, I also grouped together emails by sender ID. Making the assumption that a person’s writing style is consistent among emails, it made sense to aggregate these together.
After running LDA (using gensim) to extract 20 topics from the emails, I found that all of the “category” texts (male, female, staffers, ambassadors) yielded the same top topic, which seemed to be generally related to government and policy.
The top 10 “words” from this topic (grammar was included as words as well):
,, ., ‘S’, 2010, AMERICAN, WORLD, PUBLIC, GOVERNMENT, OBAMA, WOULD, NEW, FIRST, POLITICAL, U.S., PEOPLE, MANY, ONE, ADMINISTRATION, POLICY, WOMEN
When taking a look at the emails Hillary sent to each of these groups, the top topic didn’t differ by gender or by group, which I thought was interesting. They also didn’t vary much by average sentence length or word length; however, the dataset of email text sent to women was double the size sent to males.
Interestingly enough, the top topic didn’t win out by too much for any one group. For females, this top group was 16% and for males it was 20%. For category texts, which contain more text than text from an individual, it makes sense that it’ll be more spread out among several topics — to remedy this, I decided to take a look at the top 5 topics instead.
Females: 1, 3, 6, 16, 4
Males: 1, 3, 6, 4, 16
So you see the same topics, with differences in topic distribution probably attributable to different jobs that males and females had in Hillary’s network.
To get a sense of where less popular topics cropped up, I had more success looking at individual senders / recipients. For example, Voda “Betty” Ebeling, one of Clinton’s long-time friend and advisor, ended up with a different top category than was different than the top topic above:
), (, Start, :, Israeli, ., 1.4, , , bill, company, deal, 2014, money, ;, palestinian, netanyahu, idea, thing, b1, strong, trip, d, direct, used, play, dollars, language, settlements, 30, jerusalem
Interestingly, the same topics show up in some order within the top 5 for almost every sender or category, although this makes sense; given that Clinton was using her server for work purposes only, it’s only logical that the emails are going to be closely related to one another and contain the same topics, like emails about scheduling or international affairs. In this way, LDA makes sense. I did the analysis using 20 topics, determining the number of topics using trial and error. Certainly, if you use more topics, as I experimented with, you’d get more granular results but would also get the same result of the same top topic across categories. If you use a smaller number of topics, you risk having topics that aren’t distinct enough (e.g. mixing together topics on domestic versus international policy).
Another approach to classification is to use k-means clustering, which partitions observations into k clusters with each observation corresponding to the cluster with the closest mean. Unlike LDA, k-means clustering is not a Bayesian method.
In my analyses, I found there was a large overlap between the cluster analysis and topic analysis, as I expected, but I found the topic analysis to be more useful and specific. When I used k-means clustering, I got more of a zoomed-out classification of topics. By using topic analysis, I got a more quantitative look at how similar a document is compared to the corpus, which proved useful given the large overlap in email content among categories of people.
Clustering yielded similar results in that I was able to see distinct clusters for some but not for others. Comparing clusters and topics, I found the top words in each topic to be similar to the words in each cluster.
To answer my question about similarities in topic, I created a visualization which compares how similar topic distribution was between males and females across topics:
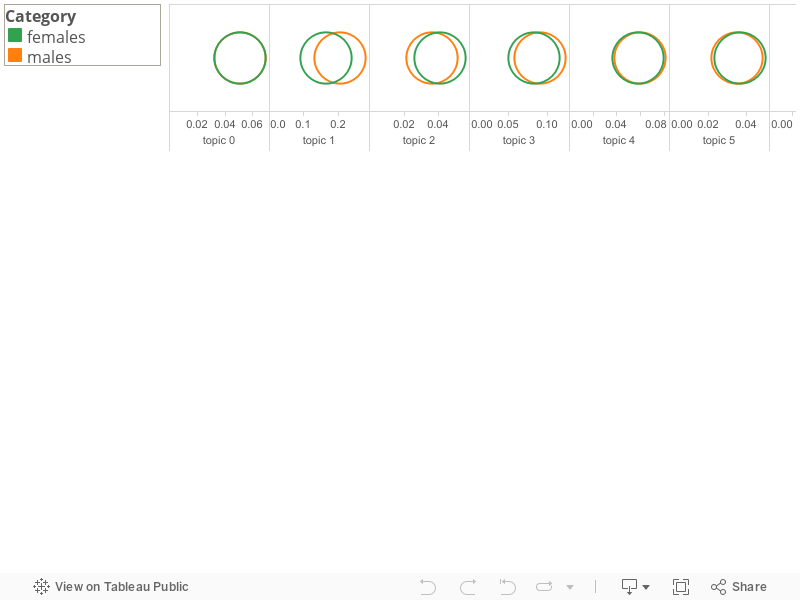
Ambassadors had this topic unique to them as a top topic:
., war, republican, “s”, groups, support, million, group, boehner, jewish, candidate, fact, control, often, among, rights, beyond, needed, isreal
Staffers have this topic unique to them:
pm, s, office, secretary, meeting, treaty, room, house, state, private, conference, department, staff, white, route, arrive, time, depart, foreign, residence
###
###
###
Vocabulary differences among categories
Aside from topics in emails across categories, I was also interested in how vocabulary differed between groups. Understanding the difference in word usage approaches differences in language from a different angle, so with that in mind, here’s what I found to investigate my hypothesis:
Words men use that women do not:

And words women use that men do not. Women use _many_ more words than men (I had to filter for words that occur at least 50 times in order to make the bubble chart more readable):
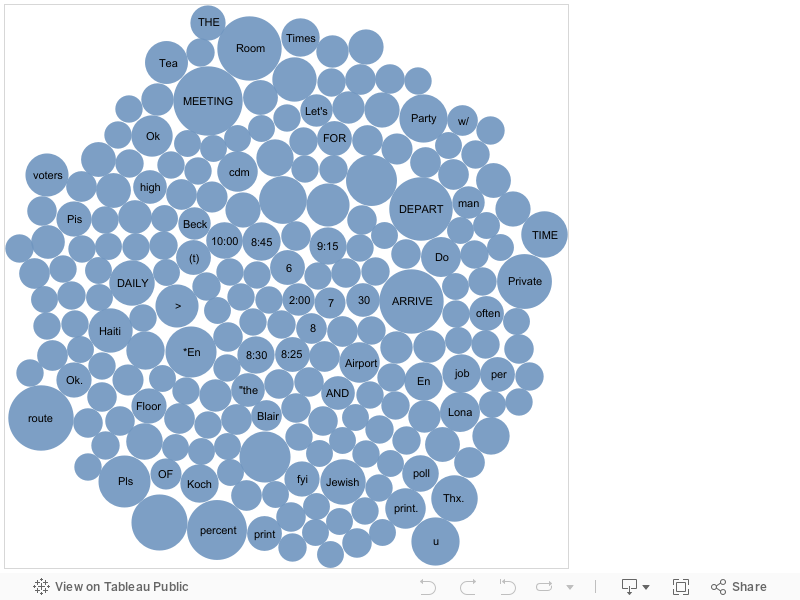
Women also use words that are more domestically inclined, like “children” and “domestic” (although the latter is likely in the context of domestic policy), and there are also a lot more times and the words “arrive” and “depart” — perhaps because Clinton’s schedulers are female.
Words that ambassadors do that staffers do not:
6805, women., 647-7288, Verveer, marriage, 647-7283, VerveerMS@state.gov, Large, Street, Verveer, NW, female, Womens
The top 50 words that staffers use that ambassadors do not:
Lona, talk, HRC, May, important, fyi, economic, right, president, national, send, today., June, FW:, IN, For, Treaty, East, set, issues, Floor, global, email, So, administration, put, give, believe, (t), 10:00, September, MINISTER, Assistant, FOR, Friday, clear, North, Thursday, statement, 8:25, April
Disclaimer: the ambassadors text file is pretty small, so this ended up being kind of a futile exercise.
###
Emails at all hours: Hillary’s emails sorted by time of day
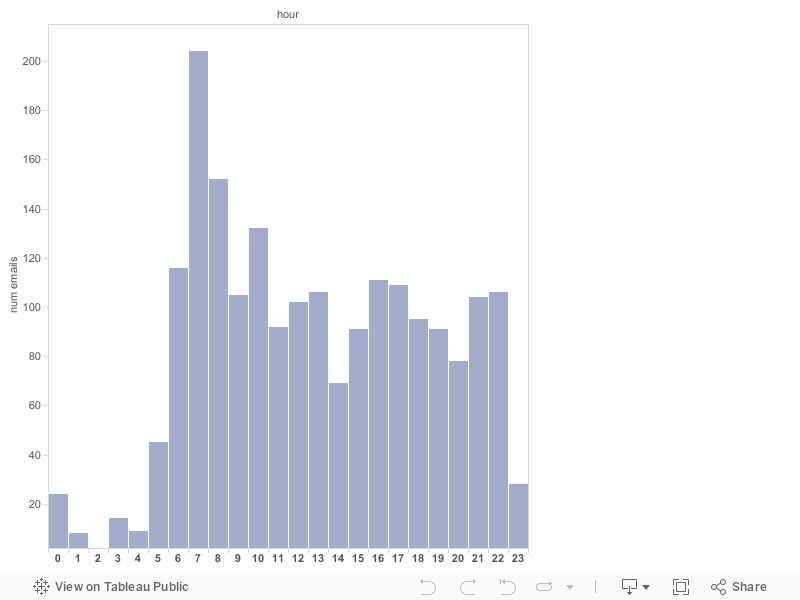
Taking a look at this graph, what’s evident is that there’s a huge number of emails sent at 7 a.m. — after that, the number of emails sent stays consistent until 11 p.m. when it drops off. Arguably, we can figure out her sleep schedule, too: she probably wakes up between 5 and 6 every day, gets to the White House by 7 and sleeps by midnight.
The mass of emails sent at 7 a.m. makes sense — they’re probably emails updating her staffers about whether she’s on time or requests to print documents by the time she gets to her desk.
Going a little further with this, let’s take a look at the top words and n-grams per hour:
Top 5 words at 7 a.m. :
[‘w’, ‘call’, ‘AM’, ‘Pls’, ‘Can’, ‘see’, ‘get’, ‘want’, ‘print’, ‘.’, “I’m”]
Average sentence length: 8.25 words
Average email length: 12 words
Pretty consistent with my hypothesis: Hillary is making requests at 7 a.m. – perhaps a printout, perhaps a rescheduling, and the “I’m” likely has to do with her whereabouts.
Let’s compare this to other times of day: the top words at 8, 9, and 10 a.m. are almost exactly the same. At about 11 a.m. things change slightly with “British” becoming a top word, but other than that the top words stay the same through — always a combination of please and thank you, calls and either “I’d” or “I’m.”
Around 4:00 p.m. things get interesting:
Top words at 4:00 p.m. :
[‘Clips’, ‘Press’, ‘Strategic’, ‘Dialogue’, ‘PM’, ‘call’, ‘w’, ‘Re:’, ‘What’, ‘Pls’]
This makes sense — the press is probably wrapping up for the day.
After, it goes back to the “pls” and “thx.”
At 7:00 p.m., “tomorrow” creeps into top words, indicating Clinton’s day is wrapping up.
After that, much of the same, with ‘tomorrow’ appearing throughout the evening hours. No matter what the hour, “print” is a top word — it’s interesting that Hillary doesn’t tend to read too many things on an electronic device.
Brevity above all: “Pls print” and “thx”
A quick pass through Clinton’s emails reveals many instances of “pls print” emails and “thx” — these emails read like texts in that they’re to the point. By the numbers:
91 emails containing “pls print”
233 emails containing “pls” vs 10 instances of “please”
199 instances of “thx” vs 55 instances of “thanks”
Not surprisingly, instances of “thx” and “pls” were limited to recipients with a state.gov email address (i.e. her staffers).
Barbara Mikulski: A short aside & serendipitous discovery
Sometimes, interesting data comes not by way of data analysis but by opening a random text file by accident and discovering an interesting exchange. I found an exchange between Clinton and Barbara Mikulski, the Democrat senator from Maryland that was heartwarming and supportive. Here’s a few excerpts of the emails (lightly edited for grammar / punctuation inconsistencies):
From: Barbara Mikulski
To: Hillary Clinton
Sent: Apr 12, 2009 12:03 PM
Subject: Happy easter
Best wishes to you and all of the clintons. All of us say a Hearty Hello and are so proud of what you are doing—-you are missed in the senate and by me. But you sure are needed where you are. I will be @ your. Foreign. Ops. Hearing. Let me know any questions you want me to ask to help get your needs/message across. Loved picture of you+obama on the lawn. Time for. Spring and the resurrection.
As always. Your Pal
Sent from my BlackBerry Wireless Handheld
From: Mikulski, BAM (Mikulski)
Sent: Tuesday, June 30, 2009 10:15 PM
To:
Subject: Re: Sorry to hear re your fall
Am so glad to hear frm you/Hi knew this was painful combined with logistics of being a woman–know. How stressful this must be—-the other night the senate women had dinner anyway—all sent good words. And encouragement. To a woman they all said. Oh my imagine just getting dressed and the hair thing. Get your therapy. Get better. The senate is slogging along, health care is starting to sag. — some days it feels like we are doing the public option off back of envelope. Call when you can. X.
Sent from my BlackBerry Wireless Handheld
Original Message
From: H HDR22@clintonemail.com
To: Mikulski, BAM (Mikulski)
Sent: Tue Jun 30 17:58:56 2009
Subject: Re: Sorry to hear re your fall
Barb–Thanks, my dear friend, for your good wishes. I am on the mend,
Let’s try again for dinner soon. Happy 4th!! All the best, Hillary
From: Mikulski, BAM (Mikulski) BAM@Mikulski.senate.gov
Sent: Monday, March 22, 2010 8:01 PM
To:
Subject Nuns. Health. Care
Whew once again u are in the thick of thing— but didn’t it make your heart feel good about the passage of health care—-and the nuns pushed it over the finish line—as usual in the core front of social justice and a daring willingness to break with the boys—— if you need a tonic. Go to the nuns exhibit @ the. Smithsonian— Ripley Center. Gives the 250 year history of Nuns in Usa and their role in shaping our country and producing 1000s of women leaders with names like. Pelosi, Mikulski, Ferrar, Sebilius. takes less than a hour. You are doing great
Sent from my BlackBerry Wireless Handheld
Data sources and future work
The data for this project came from Kaggle’s dataset which aggregated the FOIA requests. This isn’t a full dataset as it doesn’t include the last batch of released emails, but I found it to be complete enough for this project. Some challenges arose when I found that a lot of metadata was missing (like date sent) or that it wasn’t in a consistent format, but I standardized the ExtractedDateSent field for most of the dataset (at the least, for all of Clinton’s sent emails) for the purpose of analyzing emails by time and have the updated dataset on github. In addition, I found that this dataset wasn’t complete in terms of emails sent, perhaps because of confidential information. For example, while there are entries for Bill Clinton and Madeleine Albright, there were no emails with that sender ID. I didn’t check through all of the original FOIA requests to see if this was a problem with Kaggle’s data set, but I did notice that those email entries were also missing from the WSJ’s interactive article.
An interesting question I wanted to approach but didn’t was how Hillary’s sentiments in emails changed among groups or particular email recipients. This problem was partially due to the lack of a training data set which I felt would tag enough of Hillary’s words (rather than leaving a large number of unknown words as neutral entries). There is a preliminary sentiment analysis on Kaggle using syuzhet, which showed a high level of trust and anticipation among emails, which makes sense given her role as a top cabinet member.
Obviously, there is a wealth of information to be explored, not only in terms Hillary’s Inbox, but also in how we analyze email text corpora. I didn’t take a look at subject lines, lengths of email threads or attachments, and this remains a relatively untouched path according to my background research. I’ll probably wrangle with this data set a bit more in the next months, seeking to address some of that untouched territory.
Thanks & acknowledgement:
Special thanks to Sravana Reddy for her support, resources and being a great sounding board when I was swimming in data! Thanks to Allen Riddell for his insights as well. This project was part of my Natural Language Processing final project at Wellesley College.